
It’s part of my job to cover the ecosystem of Hadoop, the open source big data technology, but sometimes it makes my head spin. If this is not your primary job, how can you possibly keep up? I hope that a discussion of what I’ve found to be most important will help those who don’t have the time and energy to devote to this wide-ranging topic.
I was a little late to the party. I first wrote about Hadoop for Ventana Research in 2010. Apache Hadoop then was about four years old and consisted of three modules with three top-level projects and a few subprojects. It didn’t reach the version 1.0 designation until a year later, in December 2011. Since then it has continued to evolve at a pace that is always steady and sometimes dizzying. Today the Apache Foundation lists four modules and 11 projects on its Hadoop page and a total of 35 projects that fall into the big data category.
The open source model has had a major impact on the big data market, yet in some ways, the open source approach has succeeded despite its shortcomings. For one thing, it is not an ideal business model. Few “pure” open source companies have been able to make a profit. Red Hat is the most notable financial success in the open source world. Hortonworks, one of the Hadoop distribution vendors, strives to be entirely open source but has struggled to make a profit.
Instead, when it comes to commercializing open source technologies, most vendors use a hybrid licensing model that combines open source components with licensed products to create revenue opportunities. So far, this model hasn’t proven to be financially viable either. Cloudera and MapR have chosen a hybrid Hadoop model, but they are private companies that don’t disclose their financials publicly. By some analysts’ estimates Cloudera won’t be profitable until 2018, and MapR has indicated it won’t have a positive cash flow until mid-2017.
The real, if nonmonetary, value of an open source model is that it helps create a large community, one that few organizations could create on their own. Here the Hadoop community is an outstanding example. The Strata+Hadoop World events will take place in five different locations this year, and organizers expect to attract a combined audience of more than 10,000 attendees. The Hadoop Summits will take place in four different cities and also attract thousands of attendees. On the adoption front, nearly half (48%) of the participants in our big data integration benchmark research said they now use Hadoop or plan to use it within 12 months.
A large community such as this one typically spawns more innovation than a small community. This is both the blessing and the curse of the Hadoop ecosystem.
Hadoop constantly changes. New projects are created as the community seeks to improve or extend the existing capabilities. For example, in many cases, the MapReduce programming model is being supplemented or replaced by Spark, as I have noted. In its original incarnation, Hadoop was primarily a batch-oriented system, but as it grew in popularity users started to apply it in real-time scenarios including Internet of Things (IoT) applications, which I’ve written about. Multiple Apache projects sprung up to deal with streaming data including Flink, Kafka, NiFi, Spark Streaming and Storm.
Regarding the last capability, all the major Hadoop distribution vendors have adopted some form of streaming data. Cloudera uses Spark and is adding Envelope and Kudu for low-latency workloads. Earlier this year, Hortonworks launched its second product, Hortonworks Data Flow, which is based on Kakfa, NiFi and Storm for streaming data. MapR introduced MapR Streams to deal with streaming data and IoT applications using the Kafka API. It’s clear that Hadoop vendors see a need to provide streaming of data, but the variety of approaches creates confusion for organizations about which approach to use.
Early Hadoop distributions did not emphasize security and governance. In our research more than half (56%) of organizations said they do not plan to deploy big data integration capabilities because it poses security risks or issues. Now those gaps are being addressed. The Apache Knox, Ranger and Sentry projects add security capabilities to Hadoop distributions. Unfortunately, there is not much consistency among vendors on which of these projects they support, again creating more confusion about which projects to use. Two other Apache projects, Atlas and Flacon, are designed to support data governance capabilities. Atlas and Ranger are still in the incubation process, the Apache process for accepting new products, but nothing prevents vendors from adopting these projects at this stage.
So how should your organization deal with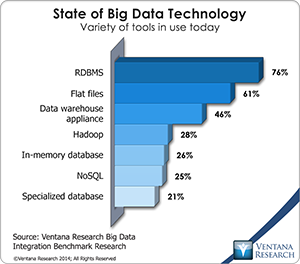 all these moving parts? Here’s my recipe. First it is important to have the skilled resources needed to manage big data projects. In our research 44 percent reported that they don’t have the Hadoop-specific skills needed. Those without them should consider hiring or contracting appropriately skilled Hadoop resources. However, some vendors provide packaged Hadoop offerings that reduce the need to have all the skills in house. For instance, there are cloud-based versions of Cloudera, Hortonworks and MapR. Amazon EMR also provides a managed Hadoop framework. Some vendors recognized the shortage of skills and have built businesses around offering big data as a service including Altiscale and BlueData.
all these moving parts? Here’s my recipe. First it is important to have the skilled resources needed to manage big data projects. In our research 44 percent reported that they don’t have the Hadoop-specific skills needed. Those without them should consider hiring or contracting appropriately skilled Hadoop resources. However, some vendors provide packaged Hadoop offerings that reduce the need to have all the skills in house. For instance, there are cloud-based versions of Cloudera, Hortonworks and MapR. Amazon EMR also provides a managed Hadoop framework. Some vendors recognized the shortage of skills and have built businesses around offering big data as a service including Altiscale and BlueData.
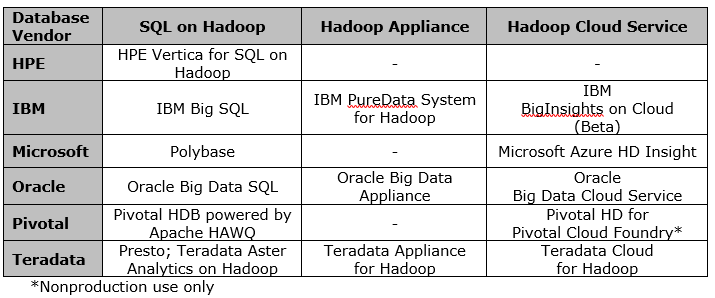
Analytic database and data warehouse vendors have also attempted to make it easier to access and take advantage of Hadoop. These products typically take the form of SQL capabilities on Hadoop, an appliance configuration that comes installed with Hadoop or a cloud-based service that includes Hadoop. This table summarizes several vendors’ offerings.
The Open Data Platform initiative (ODPi), an industry consortium, attempts to reduce the skills needed to master different projects and versions within the Hadoop ecosystem by defining specifications for a common set of core Hadoop components. Currently Hortonworks and IBM offer ODPi-compliant versions of their Hadoop distributions, but Cloudera and MapR do not. The specification provides value to those who are looking for stable versions of the core Hadoop components.
The SQL on Hadoop products mentioned above still require that an organization have Hadoop, but it is worth considering whether you need Hadoop at all. Snowflake Computing was founded on the premise that organizations want to take advantage of the SQL skills they already have. This vendor built a cloud-based elastic data warehouse service that can scale and accommodate diverse data types while retaining a SQL interface. This approach may not be far-fetched; our research shows that relational databases are still the most commonly used big data technology.
To say the least, the Hadoop ecosystem is varied and complex. The large community surrounding big data continues to produce innovations that add to the complexity. While organizations can derive significant value from Hadoop, it does require investment. As your organization considers its investments in big data, determine which approach best suits its requirements and the skills available.
Regards,
David Menninger
SVP & Research Director
Follow Me on Twitter @dmenningerVR and Connect with me on LinkedIn.

David Menninger
Executive Director, Technology Research
David Menninger leads technology software research and advisory for Ventana Research, now part of ISG. Building on over three decades of enterprise software leadership experience, he guides the team responsible for a wide range of technology-focused data and analytics topics, including AI for IT and AI-infused software.








