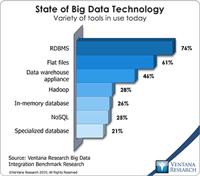
It’s part of my job to cover the ecosystem of Hadoop, the open source big data technology, but sometimes it makes my head spin. If this is not your primary job, how can you possibly keep up? I hope that a discussion of what I’ve found to be most important will help those who don’t have the time and energy to devote to this wide-ranging topic.
Read More
Topics:
Big Data,
Microsoft,
Teradata,
Business Analytics,
Business Intelligence,
IBM,
Information Management,
Operational Intelligence,
Oracle,
HPE,
ODPI,
Strata+Hadoop
Data virtualization is not new, but it has changed over the years. The term describes a process of combining data on the fly from multiple sources rather than copying that data into a common repository such as a data warehouse or a data lake, which I have written about. There are many reasons for an organization concerned with managing its data to consider data virtualization, most stemming from the fact that the data does not have to be copied to a new location. It could, for instance,...
Read More
Topics:
Big Data,
Business Analytics,
Business Intelligence,
Data Integration,
Data Lake,
Information Applications,
Information Management,
Data Virtualization