Alteryx Inspire 2019, this year's user conference for Alteryx, drew around 4500 customers, partners, and prospects to Nashville’s Gaylord Opryland Resort & Convention Center in Tennessee last month. The strong attendance was a reflection of the strong growth Alteryx has experienced over the last year; roughly 50% growth year-over-year. This year's conference focused on Alteryx's evolution from data preparation to AI and machine learning, and both were front and center.
Read More
Topics:
Big Data,
Data Science,
alteryx,
Machine Learning,
Data Integration,
Data Management,
Alteryx Inspire
In 2017 Strata + Hadoop World was changed to theStrata Data Conference. As I pointed out in mycoverage of last year’s event, the focus was largely on machine learning and artificial intelligence (AI). That theme continued this year, but my impression of the event was of a community looking to get value out of data regardless of the technology being used to manage that data. The change was subtle: The location was the same; the exhibitors were largely the same; attendance was similar this year...
Read More
Topics:
Big Data,
Data Science,
Machine Learning,
Analytics,
Business Intelligence,
Data Governance,
Data Integration,
Data Preparation,
Information Optimization,
Digital Technology,
Machine Learning and Cognitive Computing
All too often, software vendors view analytics as the end rather than the beginning of a process. I’m reminded of some of the advanced math classes I’ve taken in which the teaching process focused on a few key aspects of a mathematical proof or solution, leaving the rest of the exercise to be worked out by the students. In other contexts, you may hear people say the numbers speak for themselves.
Read More
Topics:
Data Science,
Machine Learning,
Analytics,
Business Intelligence,
Collaboration,
Data Governance,
Information Optimization,
Digital Technology,
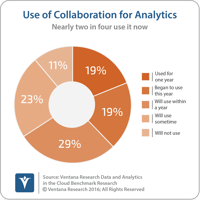
collaboration for business
We at Ventana Researchrecently published our research agendas for 2018. Analytics and business intelligence are evolving and so is our research on their use across practice areas. Earlier research has shown that analytics can deliver significant value to organizations; for example, ourpredictive analytics research shows that 57 percent of organizations reported achieving a competitive advantage and half created new revenue opportunities with predictive analytics. Waves of investment in...
Read More
Topics:
Machine Learning,
Analytics,
Business Intelligence,
Collaboration,
Internet of Things,
IOT,
Artificial intelligence,
natural language processing,
Natural Language Query
I recently attended SAP TechEd in Las Vegas to hear the latest from the company regarding its analytics and business intelligence offerings as well as its data management platform. The company used the event to launchSAP Data Hub and made several other data and analytics announcements that I’ll cover below.
Read More
Topics:
Big Data,
SAP,
Machine Learning,
Analytics,
Data Preparation
The Strata Data Conference is changing and it’s changing in a good way. At the recent Strata Data Conference in New York, Mike Olson, chief strategy officer at Cloudera, which co-sponsored the event, commented that at prior events we used to talk about the “Hadoop zoo animals,” meaning the various components of the Hadoop ecosystem of which I have written previously. Following last fall’s Strata event, I observed that the conference was evolving to focus on the use of data. Advancing that...
Read More
Topics:
Big Data,
Machine Learning,
Analytics,
Hadoop,
Artificial intelligence,
Strata Data Conference
Recently Hortonworksannounced some significant additions to its products at the DataWorks Summit. These additions reflect the fact that the big data market continues to evolve, as I have previouslywritten.
Read More
Topics:
Big Data,
Machine Learning,
Analytics,
Hadoop
Natural language generation (NLG), the process of generating text or narratives based on a set of data values, can reach a broader audience. NLG narratives can be used for a variety of purposes, but in this perspective I focus on how NLG can be used to enhance business intelligence (BI) processes. In the case of BI, NLG can be used to explain what has happened and why it is happening, and even what actions to take. The NLG narratives can be understood by a broader range of business users than...
Read More
Topics:
Machine Learning,
Natural Language,
Analytics,
Business Intelligence,
NLG
Big data initially was characterized in terms of “the three V’s,” volume, velocity and variety. Nearly five years ago I wrote about the three V’s as a way to explain why new and different technologies were needed to deal with big data. Since then the industry has tackled many of the technical challenges associated with the three V’s. In 2017 I propose that we focus instead on a different letter, which includes these A’s: analytics, awareness, anticipation and action. I’ll explain why each is...
Read More
Topics:
Data Science,
Machine Learning,
Analytics,
Business Intelligence,
Collaboration,
Data Preparation,
Internet of Things,
Information Optimization
IBM recently held its inaugural World of Watson event. Formerly known as IBM Insight, and prior to that IBM Information on Demand, the annual event, attended by 17,000 people this year, showcases IBM’s data and analytics and the broader IBM efforts in cognitive computing. The theme for the event, as you might guess, was the Watson family of cognitive computing products. I, for one, was glad to spend more time getting to know the Watson product line, and I’d like to share some of my observations...
Read More
Topics:
Big Data,
Data Science,
Machine Learning,
Analytics,
Cloud Computing,
Data Governance,
Data Integration,
Internet of Things,
Information Optimization,
Digital Technology