Organizations are increasingly using data as a strategic asset, which makes data services critical. Huge volumes of data need to be stored, managed, discovered and analyzed. Cloud computing and storage approaches provide enterprises with various capabilities to store and process their data in third-party data centers. The advent of data platforms previously discussed here are essential for organizations to effectively manage their data assets.
Read More
Topics:
embedded analytics,
Analytics,
Business Intelligence,
Collaboration,
Data Governance,
Data Lake,
Data Preparation,
Data,
AI & Machine Learning,
Microsoft Azure
A data lake is a centralized repository designed to house big data in structured, semi-structured and unstructured form. I have been covering the data lake topic for several years and encourage you to check out an earlier perspective called Data Lakes: Safe Way to Swim in Big Data? for background. Our data lake research has uncovered some points to consider in your efforts, and I’d like to offer a deeper dive into our findings.
Read More
Topics:
Data Governance,
Data Lake,
Information Management,
Data,
Digital Technology
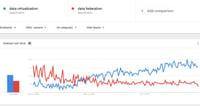
Data virtualization is not new, but it has changed over the years. The term describes a process of combining data on the fly from multiple sources rather than copying that data into a common repository such as a data warehouse or a data lake, which I have written about. There are many reasons for an organization concerned with managing its data to consider data virtualization, most stemming from the fact that the data does not have to be copied to a new location. It could, for instance,...
Read More
Topics:
Big Data,
Business Analytics,
Business Intelligence,
Data Integration,
Data Lake,
Information Applications,
Information Management,
Data Virtualization
It has been more than five years since James Dixon of Pentaho coined the term “data lake.” His original post suggests, “If you think of a data mart as a store of bottled water – cleansed and packaged and structured for easy consumption – the data lake is a large body of water in a more natural state.” The analogy is a simple one, but in my experience talking with many end users there is still mystery surrounding the concept. In this post I’d like to clarify what a data lake is, review the...
Read More
Topics:
Big Data,
Data Science,
Predictive Analytics,
Social Media,
Business Analytics,
Business Intelligence,
Data Governance,
Data Lake,
Governance, Risk & Compliance (GRC),
Information Management,
Uncategorized,
Strata+Hadoop