

Organizations are collecting data from multiple data sources and a variety of systems to enrich their analytics and business intelligence (BI). But collecting data is only half of the equation. As the data grows, it becomes challenging to find the right data at the right time. Many organizations can’t take full advantage of their data lakes because they don’t know what data actually exists. Also, there are more regulations and compliance requirements than ever before. It is critical for organizations to understand the kind of data they have, who is handling it, what it is being used for and how it needs to be protected. They also have to avoid putting too many layers and wrappers around the data as it can make the data difficult to access. These challenges create a need for more automated ways to discover, track, research and govern the data.
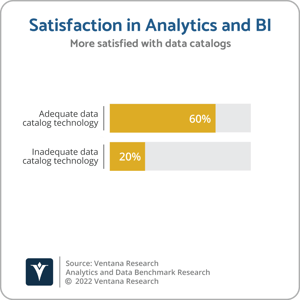 Data catalogs have become the standard for maintaining metadata for data analytics and self-service BI. They provide a roadmap to all the data sources, both internal and external, and enable data professionals and business users to swiftly sort through the inventory of data assets to find the information they need. Our Analytics and Data Benchmark Research finds that organizations with adequate data catalog technologies reported significantly higher rates of satisfaction (60% compared to 20% of those with inadequate technologies). But, considering the volume and variety of data that organizations deal with today, it becomes difficult to keep the data catalogs regularly updated. Manually searching the database and linking all metadata to the data catalog is a time-consuming and resource-intensive process. And the challenges are further magnified when organizations look to scale such manual methods as the data volume, complexity and sources increase.
Data catalogs have become the standard for maintaining metadata for data analytics and self-service BI. They provide a roadmap to all the data sources, both internal and external, and enable data professionals and business users to swiftly sort through the inventory of data assets to find the information they need. Our Analytics and Data Benchmark Research finds that organizations with adequate data catalog technologies reported significantly higher rates of satisfaction (60% compared to 20% of those with inadequate technologies). But, considering the volume and variety of data that organizations deal with today, it becomes difficult to keep the data catalogs regularly updated. Manually searching the database and linking all metadata to the data catalog is a time-consuming and resource-intensive process. And the challenges are further magnified when organizations look to scale such manual methods as the data volume, complexity and sources increase.
Artificial intelligence and machine learning (AI/ML) are transforming the data catalog landscape. Machine learning algorithms can be trained to browse through data catalogs to collect metadata and keep it updated with new, incoming information. AI/ML learns from data patterns, queries and interactions to support both data quality and governance. It enables organizations to expand the available data variety, standardize data semantics and simplify data accessibility. Many organizations have started embracing more sophisticated catalogs with AI/ML capabilities to scale operations and harness insights that would otherwise be overlooked.
 Data management vendors are continuously improving AI/ML capabilities and integrating them into their offerings to enable users to discover, refine, explore and analyze data sets more rapidly and efficiently. AI/ML make it possible for organizations to democratize data, allowing users to easily navigate unstructured data, uncover patterns in data sets and understand the movement and transformation of data through time and data lineage. We assert that by 2025, more than two-thirds of all data processes will use AI/ML to boost the value that can be derived from the data.
Data management vendors are continuously improving AI/ML capabilities and integrating them into their offerings to enable users to discover, refine, explore and analyze data sets more rapidly and efficiently. AI/ML make it possible for organizations to democratize data, allowing users to easily navigate unstructured data, uncover patterns in data sets and understand the movement and transformation of data through time and data lineage. We assert that by 2025, more than two-thirds of all data processes will use AI/ML to boost the value that can be derived from the data.
Additionally, AI/ML can automate identification and tagging of data. It detects unusual usage as well as identify sensitive data and assign protection schemes. AI/ML can assist with many data processes beyond just data privacy. It provides recommendations on what data sources to use and how to use data. It can access data quality and resolve quality issues. With an AI-driven data catalog, organizations can simplify data compliance and governance and standardize the way data is stored and labelled.
A data catalog should be a component of every organization’s data governance framework. Many vendors offer integrated data catalog capabilities for data governance, analytics and BI. Organizations should evaluate the AI/ML capabilities of the data catalog technologies they consider and how they can make it easier to find and use data, which will help improve operational results.
Regards,
David Menninger
Authors:

David Menninger
Executive Director, Technology Research
David Menninger leads technology software research and advisory for Ventana Research, now part of ISG. Building on over three decades of enterprise software leadership experience, he guides the team responsible for a wide range of technology-focused data and analytics topics, including AI for IT and AI-infused software.








