

Artificial intelligence (AI) has evolved from a highly specialized niche technology to a worldwide phenomenon. Nearly 9 in 10 organizations use or plan to adopt AI technology. Several factors have contributed to this evolution. First, the amount of data they can collect and store has increased dramatically while the cost of analyzing these large amounts of data has decreased dramatically. Data-driven organizations need to process data in real time which requires AI. In addition, analytics vendors have been augmenting business intelligence (BI) products with AI. And recently, ChatGPT has raised awareness of AI and instigated research and experimentation into new ways in which AI can be applied. This perspective, the second in a series on generative AI, introduces some of the concepts behind ChatGPT, including large language models and transformers. Understanding how these models work can help provide a better understanding of how they should be applied and what cautions are necessary.
Language models break down sentences into components, such as words, punctuation, and other elements of language, called tokens. The probability of each token following other tokens is computed by training the model over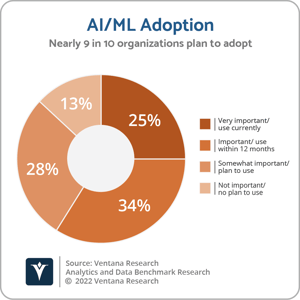 very large amounts of input, hence the name, large language models (LLMs). The probability of each token is used to predict, one token at a time, what the next portion of the response should be. Typically, the token with the highest probability is used as the next part of the response. This process is repeated continuously until the response is completed. The architecture behind most LLMs is the transformer architecture. Transformers use a variety of mathematical techniques to learn context and track relationships in sequential data. And, as you might imagine, the sequences can be many steps removed from the previous or next token.
very large amounts of input, hence the name, large language models (LLMs). The probability of each token is used to predict, one token at a time, what the next portion of the response should be. Typically, the token with the highest probability is used as the next part of the response. This process is repeated continuously until the response is completed. The architecture behind most LLMs is the transformer architecture. Transformers use a variety of mathematical techniques to learn context and track relationships in sequential data. And, as you might imagine, the sequences can be many steps removed from the previous or next token.
These models are trained on billions or even trillions of tokens. And the resulting models contain billions of parameters used in the transformation process. One of the challenges of LLMs is the process of performing this large training process. It requires a massive amount of computer resources and is not instantaneous. Therefore, these models are referred to as generative pre-trained transformers (GPT). It’s been estimated that training a model like ChatGPT would cost millions of dollars. As a result of the cost and effort involved, multiple vendors are beginning to offer GPT-based products and services. OpenAI is the vendor that introduced ChatGPT and licenses the OpenAI API and a set of pre-trained models. Microsoft has invested in OpenAI and offers Azure OpenAI Service. Google is developing Bard, currently in the experimental phase, for conversational AI. Salesforce launched Einstein GPT which incorporates OpenAI.
A challenge with transformers is that while the output may be grammatically correct and appear to be logical, it may not be entirely accurate. OpenAI is clear with users about the limitations of ChatGPT, noting that it “may produce inaccurate information about people, places, or facts” and “may occasionally generate incorrect information.” Similarly, Google notes that Bard “may give inaccurate or inappropriate responses.” Meanwhile, Microsoft notes that the new Bing “will sometimes misrepresent the information it finds, and you may see responses that sound convincing but are incomplete, inaccurate, or inappropriate,” adding that a user should, “use your own judgment and double check the facts before making decisions or taking action based on Bing’s responses.” These errors can result from the fact that the training base may have contained errors or inaccurate information. The errors can result from the fact that the responses are based on probabilities, which are never 100%. Therefore, organizations must be careful in how much reliance they place on the output of transformers that were pre-trained by third parties. One way to improve the models is to train them on information that is known to be highly accurate. For example, organizations may have training and operations manuals that could be used as the basis for creating an LLM specific to a particular organization or domain. Databricks recently introduced Dolly, an open-source LLM to provide exactly this type of capability. The intent is that organizations could create their own customized LLMs.
As organizations adopt LLMs and generative AI, it is important they do so with awareness. They should be aware of how the models were trained and the implications of the accuracy of the responses. They should be aware of how they interact with the models. In particular, are there any governance issues applying the models to their data? If the models are applied by a third party, is the organization’s data transferred to the third party? Can the output of the models be explained and can bias be detected and prevented?
LLMs are an exciting new development in the world of AI, with the potential to transform many aspects of how individuals interact with technology of all types. LLMs may be the breakthrough we need to make natural language processing (NLP) much more widely used. Prior to LLMs, NLP solutions often required a significant amount of effort to set up. The models could not easily determine synonyms and did not easily understand the specific taxonomy and terminology of individual organizations. To overcome these limitations, the synonyms and taxonomy needed to be loaded into the system and maintained. Prior to LLMs, NLP solutions were primarily English-only, as vendors struggled to get one language working well before expanding to others. Generative AI using LLMs can help overcome these challenges.
Stay tuned. This is clearly an area to watch, and there will certainly be continued investment and development of new capabilities. Each organization should understand how this technology is developing and how it may benefit them so they can be prepared to adopt it as and when appropriate.
Regards,
David Menninger
Authors:

David Menninger
Executive Director, Technology Research
David Menninger leads technology software research and advisory for Ventana Research, now part of ISG. Building on over three decades of enterprise software leadership experience, he guides the team responsible for a wide range of technology-focused data and analytics topics, including AI for IT and AI-infused software.








