

In 2017 Strata + Hadoop World was changed to the Strata Data Conference. As I pointed out in my coverage of last year’s event, the focus was largely on machine learning and artificial intelligence (AI). That theme continued this year, but my impression of the event was of a community looking to get value out of data regardless of the technology being used to manage that data. The change was subtle: The location was the same; the exhibitors were largely the same; attendance was similar this year and last. But there was no particular vendor or technology dominating the event.
Hadoop has not disappeared, as I have written previously. It was still well represented with Cloudera and MapR at the top sponsorship levels and Hortonworks exhibiting. Hadoop ecosystem partners such as Waterline Data and Zaloni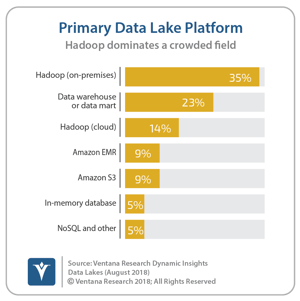 participated, offering data lake management and big data catalog solutions.
participated, offering data lake management and big data catalog solutions.
Our Data Lake Dynamic Insights research shows that Hadoop is the most common primary data lake platform in use by organizations today. But many are using other technologies and they were represented at the event also. MemSQL, an in-memory SQL database vendor, had a large presence. And new vendors such as Yellowbrick Data are securing funding and emerging to pursue the data warehouse and data mart market. Even Hadoop distribution providers such as Cloudera were touting their relational data warehouse products. The relational database is not dead yet.
The conference also attracts streaming data vendors such as Confluent and Streamlio. Data is constantly being generated by IoT and mobile devices, websites, IT systems and social media streams. These streams are part of what makes nearly all data “big” today. In our Internet of Things benchmark research, more than 90 percent of participants said that speeding the flow of information is critical to their organization, allowing them to react to opportunities before it’s too late. These streaming data vendors are seeking to capitalize on this opportunity and meet the needs of those organizations.
All the data being generated and collected needs to be integrated and prepared for analysis. Our Data Preparation benchmark research shows that nearly half (46%) of organizations are using data preparation technologies to work with big data and more than half (53%) indicate that it is important to their organization to process large volumes of data. Informatica, Talend, Tamr and Trifacta were all present at the event with tools targeted at big data preparation and data preparation in general.
Machine learning and AI are still a very significant part of the agenda. At least 10 vendors offered products focused specifically on machine learning and AI and numerous other vendors positioned their products as supporting machine learning and AI. At one point during her keynote, Hillary Mason of Cloudera asked the audience how many were actively involved in a data science project and it appeared that about half the audience raised their hands.
But this is still a new market. Our Machine Learning Dynamic Insights research shows that only about one-third of participants (31%) have been using machine learning for more than two years. There is still a lot of work to do to deepen the use of machine learning and AI, but 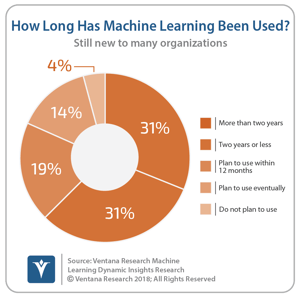 there are certainly real projects in production with real results. Domino Data Lab and Oracle’s DataScience.com are a couple of the companies focused on operationalizing and broadening the use of data science capabilities such as machine learning and AI.
there are certainly real projects in production with real results. Domino Data Lab and Oracle’s DataScience.com are a couple of the companies focused on operationalizing and broadening the use of data science capabilities such as machine learning and AI.
Business intelligence and analytics vendors participated too. The event included not just newer analytics vendors such as Arcadia Data and Zoomdata that have grown up with the big data market, but established analytics vendors such as MicroStrategy and SAS.
All in all, many parts of the data and analytics ecosystem were represented, providing a relatively complete picture of the collection and use of data in organizations today. As the Strata Conference organizers recognize, big data is becoming just data. All organizations have a need for big data, but it is no longer an exceptional thing that requires its own event. What it does require is an understanding of how the various parts of an information architecture that includes big data should come together. The Strata Data Conferences provide a good opportunity to gather some of that information.
Regards,
David Menninger
SVP & Research Director
Authors:

David Menninger
Executive Director, Technology Research
David Menninger leads technology software research and advisory for Ventana Research, now part of ISG. Building on over three decades of enterprise software leadership experience, he guides the team responsible for a wide range of technology-focused data and analytics topics, including AI for IT and AI-infused software.








